8 Essential Computer Vision Papers I Read as a CS Undergrad: From VAE to DiT
Here are 8 essential computer vision papers I read that forms the foundation of modern computer vision / generative models; in chronological order.
- Variational Autoencoder (VAE) (2013)
- Denoising Diffusion Probabilistic Models (DDPM) (2020)
- Vision Transformer (ViT) (2020)
- Contrastive Language-Image Pretraining (CLIP) (2021)
- Classifier-Free Guidance (CFG) (2021)
- Masked Autoencoder (MAE) (2021)
- Latent Diffusion Models (LDM) (2022)
- Diffusion Transformer (DiT) (2022)
Modern computer vision and generative modeling evolved through a sequence of connected breakthroughs. In 2013, the Variational Autoencoder (VAE) introduced probabilistic latent-variable modeling and the Evidence Lower Bound (ELBO), providing a practical framework for learning continuous latent representations. Instead of mapping an image into a fixed deterministic vector, VAE modeled the latent space as a distribution, which later became important for scalable generative models and latent-space compression.
For several years, generative models struggled with either unstable training, low sample quality, or limited diversity. In 2020, Denoising Diffusion Probabilistic Models (DDPM) changed the direction of the field by framing image generation as iterative denoising. Rather than generating an image in a single step, DDPM learned to reverse a Markov noising process and gradually recover data from Gaussian noise. Diffusion models produced significantly higher visual fidelity and more stable training behavior than many previous approaches, quickly becoming one of the dominant paradigms in image synthesis. However, diffusion models were computationally expensive because the generation process required many sequential denoising steps and operated directly in high-dimensional pixel space.
During the same period, Vision Transformer (ViT) introduced transformers into computer vision by treating image patches as token sequences. This reduced dependence on convolutional inductive bias and showed that transformer scaling behavior could extend beyond natural language processing. In 2021, Masked Autoencoders (MAE) further strengthened transformer-based vision learning through self-supervised masked reconstruction, allowing ViTs to learn efficient image representations from large-scale unlabeled data. Together, ViT and MAE established transformers as scalable backbone architectures for future generative vision systems.
Also in 2021, CLIP replaced closed-set classification objectives with contrastive image-text representation learning. Instead of predicting fixed labels, CLIP learned a shared embedding space between images and natural language, which later became critical for prompt-conditioned image generation systems. In the same year, Classifier-Free Guidance (CFG) solved another major limitation of diffusion models: weak conditional control. By combining conditional and unconditional diffusion predictions during sampling, CFG greatly improved prompt alignment without requiring an external classifier, making controllable text-to-image generation practical.
In 2022, Latent Diffusion Models (LDM) combined many of these developments into a single efficient framework. LDM used VAE-based latent compression to avoid diffusion in pixel space, reducing computational cost while preserving image quality. It used DDPM-style denoising as the generative mechanism and relied on CLIP-based text conditioning together with CFG-based sampling guidance for controllable generation. LDM demonstrated that high-resolution text-to-image synthesis could become both practical and scalable, and it became the foundation of systems such as Stable Diffusion.
Later in 2022, Diffusion Transformers (DiT) replaced the U-Net diffusion backbone with transformer architectures derived from the ViT lineage. DiT showed that transformers were not only effective for representation learning, but also highly scalable for diffusion-based image generation itself. This marked a broader transition toward transformer-native generative vision systems and influenced later work in image, video, and multimodal generation.
This blog post goes through the core ideas, mathematical formulations, and architectural contributions introduced by each paper, with a focus on how these works connect to each other historically and technically. Rather than treating these papers as isolated breakthroughs, the goal is to examine how concepts such as latent-variable modeling, diffusion-based generation, transformer architectures, self-supervised learning, and multimodal conditioning gradually built the foundation of modern computer vision and generative AI systems. Through this progression, the post introduces eight papers that significantly influenced my understanding of the field.
1. Variational Autoencoder (VAE)
A VAE learns an encoder that maps data into a latent distribution and a decoder that reconstructs samples from latent variables. Instead of learning a deterministic representation, VAE approximates the intractable posterior
\[q_\phi(z|x)\approx p_\theta(z|x)\]where the true posterior and the margianl likelihood are generally expensive to compute exactly.
\[p_\theta(z|x) = \frac{p_\theta(x|z)p(z)}{p_\theta(x)} \qquad p_\theta(x) = \int p_\theta(x|z)p(z)dz\]VAE therefore introduces variational inference and optimizes the Evidence Lower Bound (ELBO) from the original paper:
\[\mathcal{L}(\theta,\phi;x^{(i)}) = - D_{KL}\left(q_\phi(z|x^{(i)})||p_\theta(z)\right) + \frac{1}{L}\sum_{l=1}^{L}\log p_\theta\left(x^{(i)}|z^{(i,l)}\right)\] \[z^{(i,l)} g_\phi\left(\epsilon^{(i,l)},x^{(i)}\right), \qquad \epsilon^{(i,l)}\sim p(\epsilon)\]This formulation introduces the following reparameterization trick which allows gradients to propagate through stochastic latent sampling during backpropagation.
\[z = \mu + \sigma\odot\epsilon, \qquad \epsilon\sim\mathcal{N}(0,I)\]Core contribution
VAE introduced:
- variational inference for deep generative models
- continuous latent-variable modeling
- the reparameterization trick for differentiable sampling
It established the idea that generation can happen inside a structured latent space rather than directly in pixel space. I cannot stretch enough the importance of this paper. It is really, REALLY important that you understnad the ELBO introduced in this paper. If you would like to dig deeper, please try out this series of blog posts by Professor Yoo.
- 초짜 대학원생의 입장에서 이해하는 Auto-Encoding Variational Bayes (VAE) (1)
- 초짜 대학원생의 입장에서 이해하는 Auto-Encoding Variational Bayes (VAE) (2)
They are written in Korean… but this is the best blog post I could find discussing VAE in such depth and detail.
2. Denoising Diffusion Probabilistic Models (DDPM)
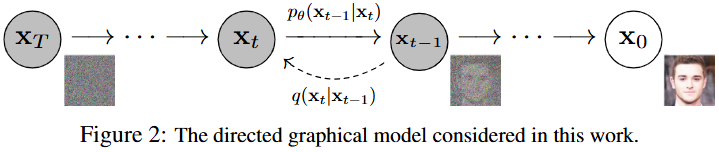
DDPM formulates image generation as iterative denoising. The forward process gradually corrupts data with Gaussian noise:
\[q(x_t|x_{t-1}) = \mathcal{N} ( x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I )\]After many timesteps $ x_T \sim \mathcal{N}(0, I) $. The model then learns the reverse process which progressively removes noise and reconstructs the data distribution. Mathematically, DDPM remains closely connected to VAE: both introduce latent variables, define tractable Gaussian transitions, and optimize variational lower bounds instead of directly maximizing the intractable data likelihood. DDPM derives a variational objective over the entire diffusion trajectory:
\[\mathcal{L}(\theta,\phi;x^{(i)}) = - D_{KL}\left(q_\phi(z|x^{(i)})||p_\theta(z)\right) + \frac{1}{L}\sum_{l=1}^{L}\log p_\theta\left(x^{(i)}|z^{(i,l)}\right)\]which is later simplified into the practical denoising objective:
\[L_{simple} = \mathbb{E}_{x_0,\epsilon,t} \left[\|\epsilon -\epsilon_\theta(x_t, t)\|^2\right]\]Instead of directly predicting images, DDPM therefore learns to predict the Gaussian noise added at each timestep.
To dive deeper, please refer to my blog post about DDPM!
3. Vision Transformer (ViT)
Before ViT, CNNs dominated computer vision because images were assumed to require convolutional inductive biases such as locality and translation equivariance. ViT challenged this assumption by treating images as token sequences.
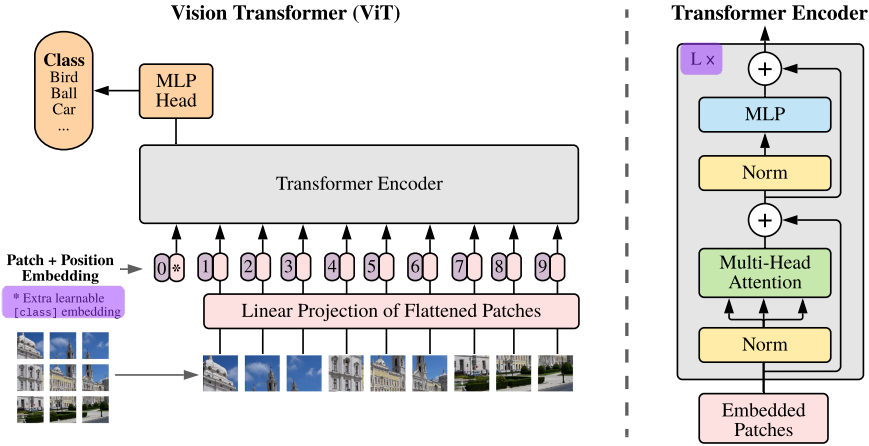
Given an image $x \in \mathbb{R}^{H \times W \times C}$, ViT partitions the image into fixed-size patches:
\[x \rightarrow {x_p^1, x_p^2, ..., x_p^N}\]Each flattened patch is linearly projected into a token embedding:
\[z_0 = [x_p^1E; x_p^2E; ...; x_p^NE] + E_{pos}\]The token sequence is then processed through transformer self-attention:
\[\text{softmax} \left( \frac{QK^T}{\sqrt d} \right)V\]The key result was not merely that transformers work for vision, but that they scale remarkably well with data and model size. ViT fundamentally changed modern vision architectures and later became the foundation for MAE, DiT, and many multimodal generative systems.
4. CLIP
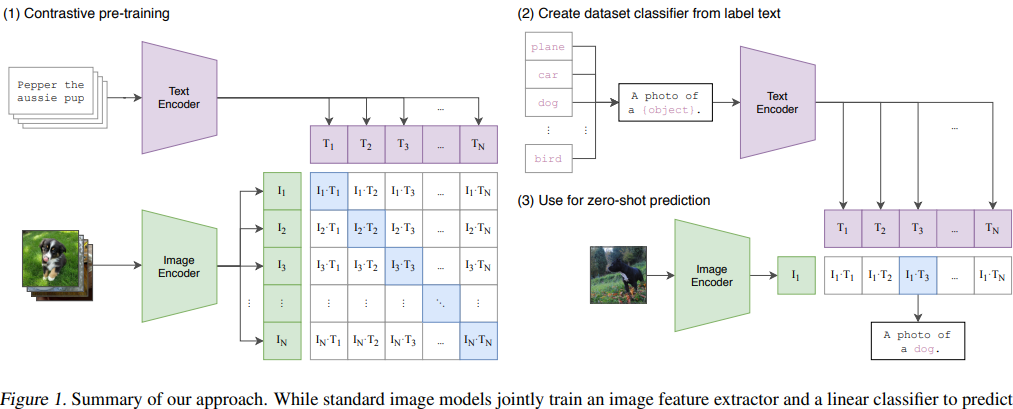
CLIP learns aligned image and text representations through contrastive learning. Instead of predicting fixed class labels, CLIP learns aligned image-text embeddings with a contrastive loss:
\[L_{\text{CLIP}} = -\frac1N \sum_i \log \frac{ \exp(\text{sim}(f(x_i),g(t_i))/\tau) }{ \sum_j \exp(\text{sim}(f(x_i),g(t_j))/\tau) }\]Instead of class labels $y\in{1,\ldots,K}$, CLIP produces a semantic conditioning vector
\[c=g(\text{prompt})\]which later becomes the text condition used in diffusion.
Core contribution
The important shift introduced by CLIP was replacing fixed-label supervision with natural language supervision at internet scale. Instead of learning closed-set classification boundaries, CLIP learned a shared semantic embedding space between images and text. This later became the conditioning interface for modern diffusion models:
\[c = f_{text}(\text{prompt})\]where text embeddings guide image generation through cross-attention and CFG-based sampling. CLIP therefore became one of the key foundations of prompt-conditioned generative systems and modern multimodal models.
5. Classifier-Free Guidance (CFG)
CFG becomes much easier to understand when viewed as a continuation of the probabilistic framework introduced by VAE and DDPM.
VAE introduced variational optimization through the ELBO:
\[\log p(x) \geq \mathbb{E}_{q(z|x)}[\log p(x|z)] - D_{KL}(q(z|x)||p(z))\]DDPM inherited this probabilistic viewpoint and derived a variational objective over the diffusion trajectory which was later simplified into the practical denoising objective:
\[L_{simple} = \mathbb{E}_{x_0,\epsilon,t} \left[ || \epsilon - \epsilon_\theta(x_t,t) ||^2 \right]\]CFG extends this same denoising framework into conditional generation by training both:
\[\epsilon_\theta(x_t,t,c), \quad \epsilon_\theta(x_t,t)\]through random condition dropping. Sampling then combines conditional and unconditional predictions:
\[\hat{\epsilon}_\theta(z_t,c) = (1+w)\epsilon_\theta(z_\lambda,c) - w\epsilon_\theta(z_t)\]where the residual term isolates the conditional signal introduced by the prompt. Earlier diffusion systems relied on external classifier gradients for guidance, but CFG removed this requirement entirely while dramatically improving prompt alignment. This simple modification became one of the most important practical advances in modern diffusion models.
6. Masked Autoencoder (MAE)
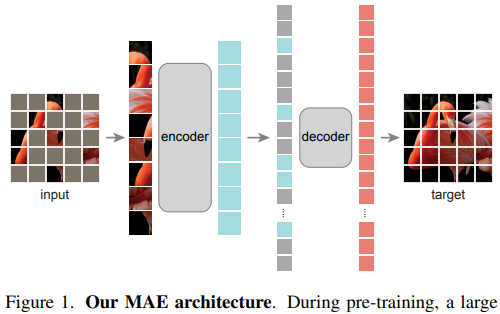
MAE performs self-supervised learning by masking a large portion of image patches and reconstructing the missing content from only the visible patches. Unlike earlier reconstruction-based methods, the encoder processes only unmasked tokens while reconstruction is delegated to a lightweight decoder, making training substantially more efficient despite very high masking ratios. This showed that transformer-based vision models could learn strong semantic representations directly from unlabeled data and significantly strengthened the ViT ecosystem. More broadly, MAE helped establish transformers as scalable visual backbones, indirectly accelerating later transformer-based generative systems such as DiT.
7. Latent Diffusion Models (LDM)
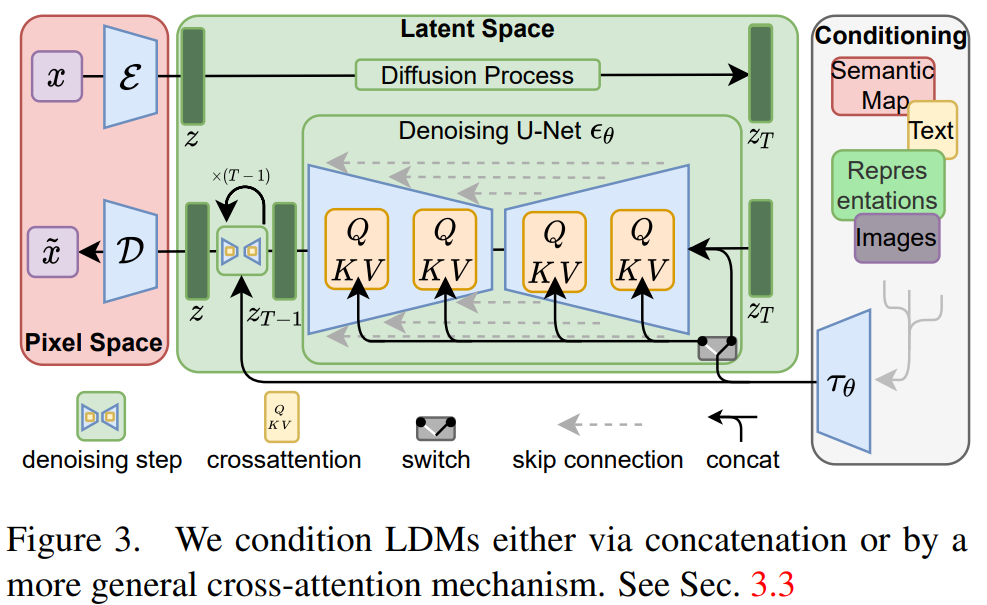
LDM compresses images into a learned latent space through an autoencoder:
\[z=\mathcal{E}(x), \qquad x=\mathcal{D}(z)\]and performs diffusion directly on latent representations rather than pixel-space tensors. Importantly, the training objective remains almost identical to DDPM:
\[L_{\text{DDPM}}\mathbb{E}\left[|\epsilon-\epsilon_\theta(x_t,t)|^2\right] \qquad L_{\text{LDM}}\mathbb{E}\left[|\epsilon-\epsilon_\theta(z_t,t,c)|^2\right]\]with the primary structural change being:
\[x_t \rightarrow z_t\]This substantially reduces computational cost by moving diffusion onto a lower-dimensional manifold while preserving high perceptual quality. Conditioning is introduced through CLIP text embeddings:
\[c=f_{\text{text}}(\text{prompt})\]and sampling is guided using CFG:
\[\hat\epsilon_\theta \epsilon_\theta(z_t,t) + w\Big( \epsilon_\theta(z_t,t,c) \epsilon_\theta(z_t,t) \Big)\]Conceptually, LDM can be viewed as the convergence of several earlier developments:
\[\text{VAE} + \text{DDPM} + \text{CLIP} + \text{CFG}\]This combination transformed diffusion models from computationally expensive research systems into practical large-scale text-to-image generators and later became the foundation of Stable Diffusion.
8. Diffusion Transformer (DiT)
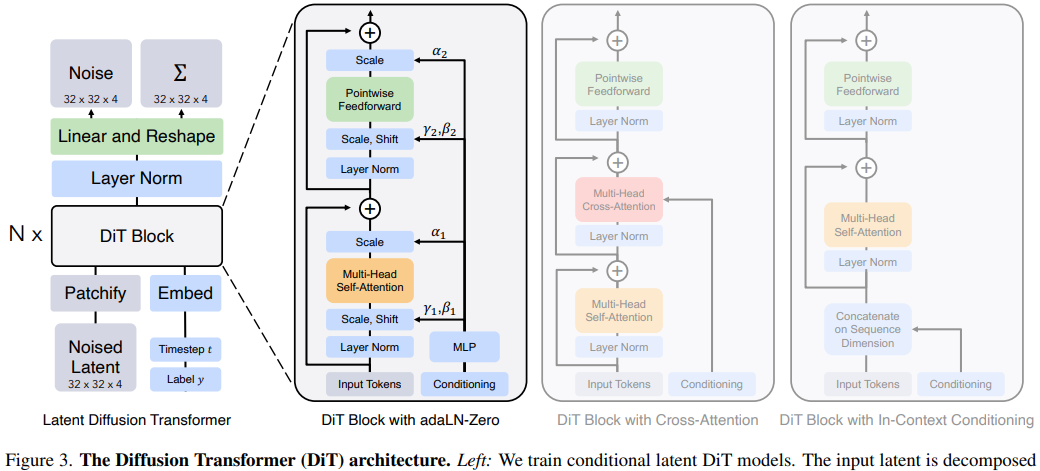
Earlier diffusion systems mainly used convolutional U-Nets as denoising backbones. DiT replaced this architecture with transformers operating directly on latent patches. DiT replaces the U-Net denoiser with a transformer over latent patches:
\[z\rightarrow\{z_p^1,\ldots,z_p^N\}\]with the same attention rule used in ViT:
\[\text{Attention}(Q,K,V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt d}\right)V\]The diffusion loss is unchanged in form:
\[L_{\text{DiT}} = \mathbb{E} \left[ \|\epsilon-\epsilon_\theta(z_t,t,c)\|^2 \right]\]The architectural change is
\[\text{U-Net}\rightarrow\text{Transformer}\]so DiT keeps the diffusion objective while swapping in a transformer backbone.
Core contribution
DiT replaced convolutional U-Nets with transformer-based diffusion backbones operating on latent patches while preserving the standard diffusion objective.
The key result was that diffusion models inherit transformer scaling behavior: performance improves predictably with model size, training compute, and dataset scale. DiT accelerated the transition toward transformer-native generative systems and strongly influenced later work in video generation, multimodal generation, and world models.
What’s Next?
1. Multimodal models
Modern systems jointly model text, images, video, audio, and actions. Representative works include GPT-4o, which unifies multimodal interaction inside a single model.
- OpenAI. (2024). Hello GPT-4o. OpenAI. https://openai.com/index/hello-gpt-4o/
2. Video generation
Image generation is rapidly extending into video generation, where the central challenges are temporal consistency, motion understanding, and world simulation. A representative example is Sora, which applies diffusion transformers to large-scale video generation.
- OpenAI. (2024). Video generation models as world simulators. OpenAI. https://openai.com/research/video-generation-models-as-world-simulators
3. Faster diffusion methods
Although diffusion models produce high-quality outputs, sampling remains expensive. Current research focuses on reducing sampling steps through methods such as Flow Matching, which reformulates generative modeling through continuous probability flows.
- Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2022). Flow matching for generative modeling. arXiv preprint arXiv:2210.02747. https://arxiv.org/abs/2210.02747
4. World models
The field is increasingly focused not only on visual quality, but also on reasoning, physical consistency, interaction, and long-horizon generation. One influential direction is Genie, which explores generative interactive world models for agents and simulation.
- Bruce, J., et al. (2024). Genie: Generative interactive environments. arXiv preprint arXiv:2402.15391. https://arxiv.org/abs/2402.15391
Final Thoughts
How naturally these papers connect into a single generative framework is truly beautiful. Each work extends and reuses ideas introduced by the previous ones. VAE introduced latent-variable inference and variational optimization. DDPM reformulated generation into probabilistic diffusion modeling. ViT and MAE showed that transformers could outperform previous convolutional architectures while introducing scaling behavior into vision. CLIP transformed natural language into a semantic conditioning interface, CFG made diffusion models practically controllable, and LDM unified these developments into an efficient latent-space generative system. Finally, DiT demonstrated that transformer scaling laws extend directly into diffusion-based image generation itself.
After reading these 8 papers, I hope you can feel how modern generative AI emerged not from a single breakthrough, but from the gradual convergence of the concepts introduced by them. It is a beautiful journey: as you move from one paper to the next, concepts, equations, and architectural decisions continuously resurface in new forms. Recognizing where those ideas originated—and seeing how later systems inherit and build upon them—brings a surprising sense of coherence and joy to whoever is trying to - or is already in - the field of computer vision.
References
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114. https://arxiv.org/abs/1312.6114
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33. https://arxiv.org/abs/2006.11239
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. https://arxiv.org/abs/2010.11929
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. Proceedings of the 38th International Conference on Machine Learning. https://arxiv.org/abs/2103.00020
- Ho, J., & Salimans, T. (2021). Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598. https://arxiv.org/abs/2207.12598
- He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2021). Masked autoencoders are scalable vision learners. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://arxiv.org/abs/2111.06377
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://arxiv.org/abs/2112.10752
- Peebles, W., & Xie, S. (2022). Scalable diffusion models with transformers. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). https://arxiv.org/abs/2212.09748
Written by
Roger Kim
