Understanding CvT: Introducing Convolutions to Vision Transformers
Convolutional Vision Transformer (CvT): Introducing Convolutions to Vision Transformers
In 2021, Vision Transformer (ViT) showed us that Transformers could be used to solve vision tasks. With deep enough models and big enough data, ViT outperformed previous SOTA models.
However, the paper (Dosovitskiy et al., 2021) made it very clear that ViTs lack CNNs’ inductive bias, thus the data-hungry nature of ViTs.
Well then, somebody must have thought of a way to integrate the inductive bias of CNNs into ViTs, right?
That’s how the Convolutional Vision Transformer (CvT) was born (Wu et al., 2021).
Architecture Overview
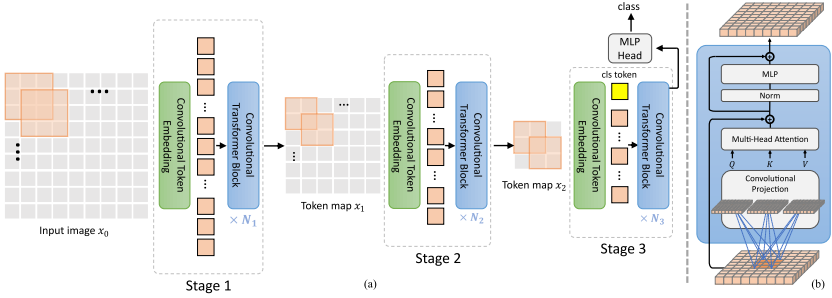
CvT follows a multi-stage hierarchical design, inspired by CNNs:
- Stage 1:
The input image is first processed by a Convolutional Token Embedding layer.- Unlike ViT’s fixed patch embedding, CvT uses overlapping convolutions, which preserve local spatial information.
- This produces the first token map $x_1$, which then passes through several Convolutional Transformer Blocks.
- Stage 2:
Another Convolutional Token Embedding downsamples and expands the representation, reducing the number of tokens while increasing feature richness.- The new token map $x_2$ again flows through Transformer blocks.
- Stage 3:
Further downsampling into a compact token map $x_3$. Then, CLS token is added before the token map is fed into the CvT block.- The output is passed through an MLP head to produce the final prediction.
Important Details
- cls token bypasses convolution projection and is reinserted before MHSA.
- Each stage is repeated $N_n$ times.
- Remember to add padding according to your kernel size.
- Size of K&V may differ from Q depending on your choice of convolutional projection
- Stride of the convolutional token embadding is explicitly defined in the paper for each model.
Convolutional Token Embedding
The Convolutional Token Embedding layer is CvT’s replacement for ViT’s patch embedding. Its goal is to model local spatial context. From low-level edges and textures to higher-order semantic patterns; while building a hierarchical representation.
- Instead of splitting an image into non-overlapping patches (as ViT does), CvT applies an overlapping convolution.
- This helps preserve neighboring relationships between pixels .
- At each stage, the convolution reduces the token sequence length while increasing feature dimensionality:
- Fewer tokens → more compact representations.
- Richer features → higher-level semantics captured.
- After convolution, the token map is flattened and normalized before being fed into Transformer blocks.
Formally,
- given the token map from the previous stage
- a 2D convolution with kernel size $s \times s$, stride $s - o$, and padding $p$ produces a new token map
- which has the height and width of:
$f(x_{i−1})$ is then flattened into size $H_i W_i × C_i$ and passed through a layer normalization.
Convolutional Transformer Block
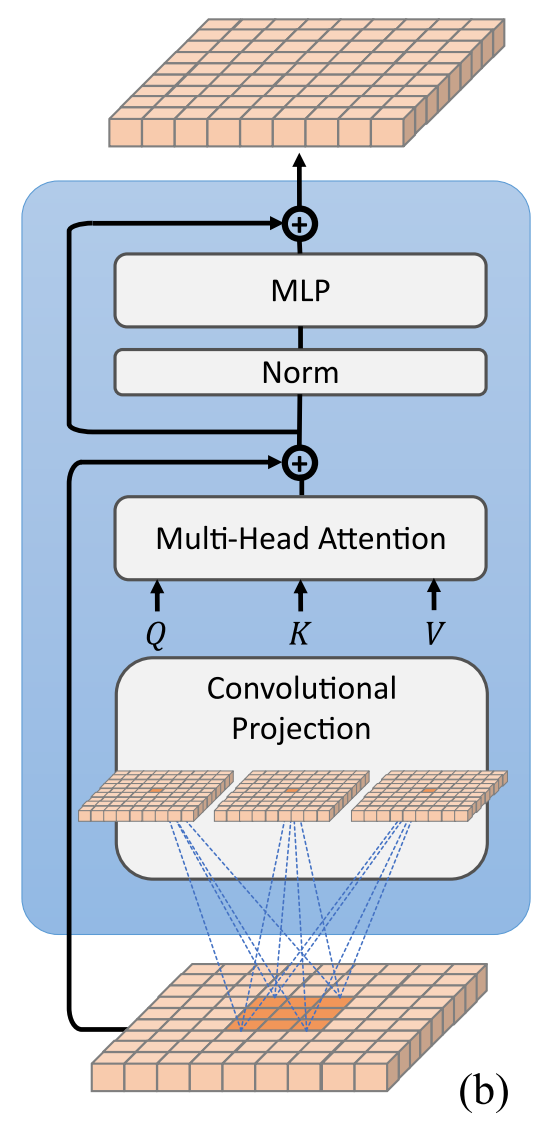
- In ViT, queries/keys/values are projected linearly.
- CvT replaces these with depth-wise separable convolutions.
- This lets attention look at local neighborhoods before going global, improving efficiency and reducing ambiguity.
Convolutional Projection
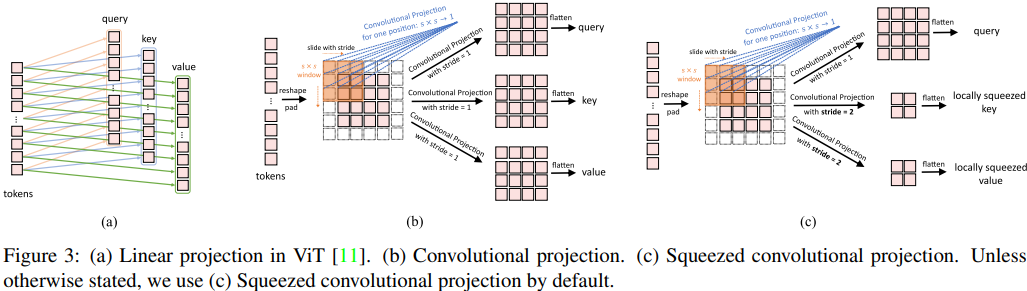
“The goal of the proposed Convolutional Projection layer is to achieve additional modeling of local spatial context, and to provide efficiency benefits by permitting the undersampling of K and V matrices” (Wu et al., 2021).
Now, you have to be careful when implementing CvT, since the paper states that they use squeezed convolutional projection by default.
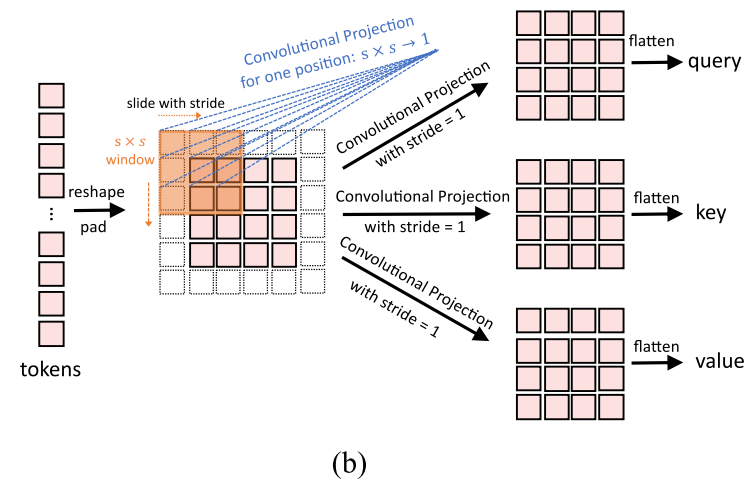
Convolutional Projection
- Replaces ViT’s linear Q/K/V with depthwise separable convolutions (stride = 1).
- Preserves full resolution for Q, K, V.
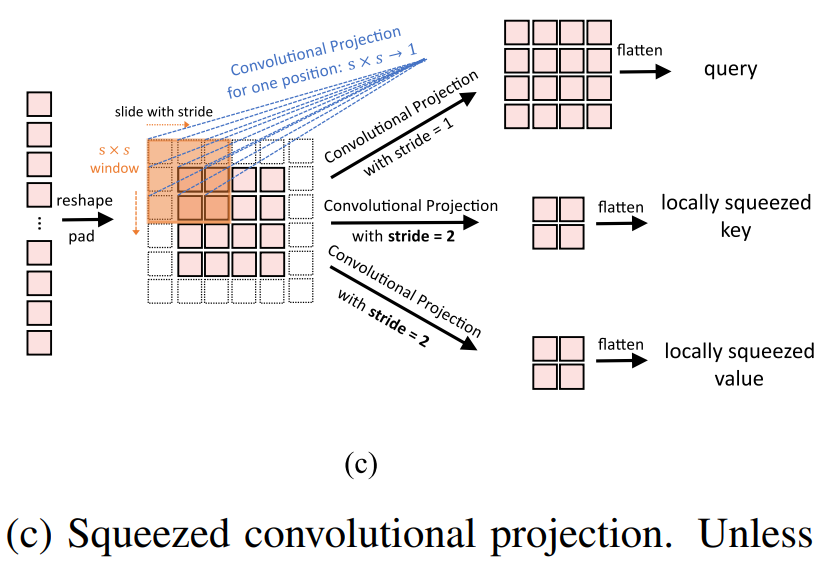
Squeezed Convolutional Projection
- Uses stride = 1 for Q, but stride = 2 for K and V (downsampled).
- Cuts K/V tokens by 4×, reducing MHSA cost.
- Benefit: ~30% fewer FLOPs, almost no accuracy loss.
Keep in mind that the paper uses squeezed convolutional projection by default.
CLS Token in Stage 3
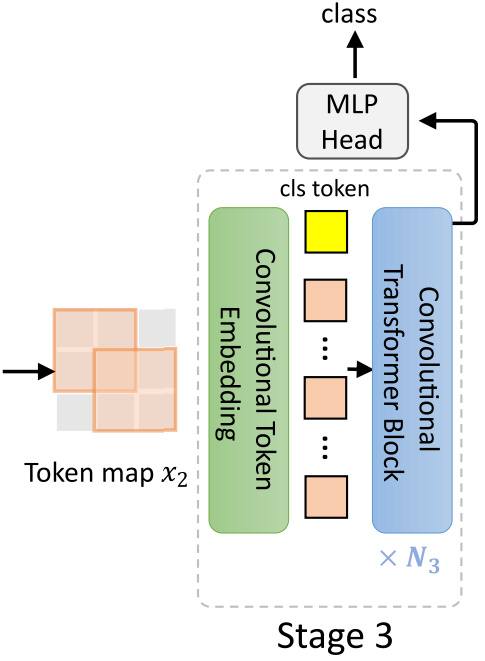
For CvTs, cls token is not added until stage 3. I will explain it in detail how cls token is passed through in each layer in stage 3. This could be a little pain in the ass when implementing.
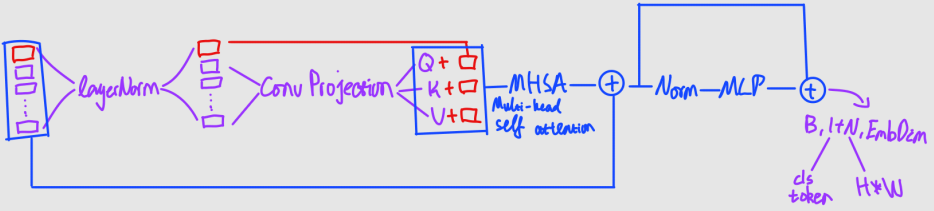
- The entire input vector goes through layer normalization.
- cls token is seperated
- The rest (spatial patches) goes through (squeezed) convolutional projection, generating Q,K,V
- cls token is concatenated back, and passed through multi-head attention layer
- Rest follows the standard transformer pattern
Results

Thankfully, the paper provided detailed architecture of each CvT model they used for training. You can go ahead and implement the model right now!
On ImageNet-1k:
- CvT-21 reaches 82.5% top-1 accuracy, outperforming DeiT-B with 63% fewer parameters and 60% fewer FLOPs.
- Even the smaller CvT-13 (20M params) beats ResNet-152, which has 3× more parameters.
On ImageNet-22k (pretraining) → fine-tuned to ImageNet-1k:
- CvT-W24 scores 87.7% top-1, surpassing ViT-L/16 by +2.5%, without using extra datasets like JFT-300M.
On transfer tasks (CIFAR, Oxford Flowers, Pets):
- CvT consistently outperforms both ViTs and ResNets, showing strong generalization.
Code Implementation
- My PyTroch implementation:
- Official Microsoft implementation:
Final Thoughts
CvT is a clever hybrid.
it keeps the scalability and global reasoning of Transformers, but regains the local structure and efficiency of CNNs.
- ViTs taught us that scale wins.
- CvT shows that inductive bias still matters — and when used strategically, it makes Transformers more data-efficient, lightweight, and robust.
References
-
Wu, H., Xiao, B., Codella, N., Liu, M., Dai, X., Yuan, L., & Zhang, L. (2021). CvT: Introducing Convolutions to Vision Transformers. arXiv preprint arXiv:2103.15808.
https://arxiv.org/abs/2103.15808 -
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. ICLR.
https://arxiv.org/abs/2010.11929
Written by
Roger Kim
